
The beauty of ideas is that they cannot die. That said, many consider the Modern Data Stack to have developed a bit of a rot1 I thought to pull out the eulogy I've had in the back of my mind for a while. It is a Tour de Links that follows the journey of the Modern Data Stack.
The analysis tracks three frameworks for mapping the cyclical nature of cultural phenomenon (one two three). These don’t map perfectly, and number three doesn’t fit the enterprise context. The idea: Something new catches on, it grows big, it loses its way, there is a fight / collapse / phase-change and then it stabilises. The subheadings are from John Cutler:
Anything helpful will eventually become commodified, industrialized, and watered down to the point of being unrecognizable. It happened with Agile, and is happening with strands of product management, DevOps, design, etc.
Phase 1: Precycle
People start a movement around a weird thing, with no hope of payoff,
for sheer love of the thing.

MDS EMERGES FROM PRACTICE
People like solving problems that resonate with other people, open source vibes, this was the early MDS scene.
Before MDS, there were enterprise data vendors and mostly they weren’t very useful for fast moving companies, in the sense that you could only afford them if you budgeted in the $xx millions and you planned in half decades. Redshift precipitated a change and Snowflake accelerated it. Pay-per-query.
Redshift and Snowflake laid the soil that led to the Modern Data Stack. They created the easiest to buy large scale data storage that anyone had ever seen. The problem now became keeping track of the transformations necessary to deal with the vast data recycling centres that were suddenly viable to be created by smaller and smaller teams.
dbt, a relatively generic idea (SQL templating in python) became the foundation for a new movement to deal with the issue, right place, people, audience, right time.
I was instantly hooked. dbt took the lead among an array of relatively fragmented solutions all jockeying around the task at hand.
MDS NAME COINED / FIRST BLOGS
A brief google and it seems like dbt first used the term "Modern Data Stack” on January 29, 2018, (I couldn’t be bothered to dig any deeper, history in the form of a sea-shanty with a broken banjo).
The concept caught on. I was working as a Data Engineer doing Redshift transformations, dbt achieved this in a far better way. Before that, doing this stuff was super expensive, testing and version control was tricky, everything was slow.
Blogs came out describing the way. Here I generously quote myself describing the series of blog posts that introduced the new way
We, the desperate, listened closely. The message I heard: bring the best of software development to startup data analytics
I was likely referring to this blog post. It all sounds rather exciting in retrospect, and it was!
MDS MINDSET / MANIFESTO / PRINCIPLES / EVANGELISTS
The whole thing coalesced (yup) around the Community. dbt slack and Locally Optimistic slack were the absolute centre(s) of the data world for a fair amount of time.
When those inside the cutting-edge scenes band together to support, teach, and create with each other, their niche and experimental projects can become the new normal on top of which the next generation builds.
The vendor guidelines kept things civil in the dbt chat, and Locally Optimistic was generally smaller and less frantic. Dbt was often the target of staffing firms who would point their junior devs at the dbt slack and say “here is your technical support” and they would paste 200 line error logs into the main chat and say “what do??” and then disappear.
I think a real kicker was the Open Source hook. Everyone wants to work with open source software. Now data people could do that!
There were reams of Guides, here is mine. (filler content for Dataform, now acquired by Google). The writing wasn’t very good in hindsight, but I stand by my suggestions, move fast with simple tools. Here is another good guide. These ideas were evaluated on some or other believability and the good ideas were amplified.
Alongside this, Validation that the data trade was noble fanned the flames.
dbt ran their first conference in 2020. 2021 they ran their second, this time it got big.
Phase 2: Growth
Because it’s so new, there is a vast frontier, waiting to be explored. Anyone willing to work hard can go to some virgin tract of ideaspace and start mining it for status. The returns on talent are high.
MDS BIG WINS
Snowflake IPO late 2020 set things in motion, the biggest software IPO ever was just the beginning of the end for MDS. dbt raised a ton of money, so did Fivetran and most of the others.
EXPLOSION OF MDS PATTERNS / BEST PRACTICES
Locally Optimistic was always and remains an ardent supporter of delivering relatively hype-free and insightful best practices. Their community remains well moderated and insightful, with very friendly and well moderated non-vendor participants. Remains a top place to visit.
Community best practices and advice about starting a company community slack started to pop up. If you were VC backed, you need 1000+ people in your slack otherwise how would you get any product feedback. This worked well in my opinion, despite the snark. If I am legitimately interested in your product I’d love to speak to the engineer building it. Companies started adding the slack activity into their go-to-market strategy, ELT’ing my activity into their CDP for better PLG or whatever.
SMALL MDS CONSULTANCIES
An acquaintance (or quite a few actually) went full throttle on consulting and quickly employed 100s of people and made a ton of revenue with massive companies.2
dbt has a huge list of vendors. This was the most reliable way to make good money in the Modern Data Stack ecosystem, but the allure of building products pulled lots of people into building data tools instead.
YOU ARE NOT DOING MDS / CERTIFICATIONS TITLES
The need to teach analysts how to be Analytics Engineers was pretty clear, they needed git, python, jinja, Data models, star schemas, denormalization, Kimball.
A few courses came out doing this stuff, first was the Analytics Engineers Club. I think the data modelling skills described are super useful, and generally fell into something that Data Engineers didn’t do and Analysts didn’t do, and so they were just ignored.
This wasn’t explicitly gatekeeping, more just demand being met by an increase in supply. I was firmly of the opinion that hiring ops people was beneficial in this space as they could easily grasp the tech and generally had a better sense for the problems that were worth addressing.
MDS VENDORS FUND CONFERENCES
There were a few smaller conferences other than Coalesce (the conference), and Snowflake summits, Data Council seemed to be the most consistently worthwhile.
In 2021 the dbt Coalesce conference peaked:
This cultural energy reaches its crescendo during Coalesce, dbt Labs’ annual conference. The conference ostensibly takes place over a number of live-streamed talks, but its beating heart is on Slack. Every talk inspires a tidal wave of excitement, encouragement, and general good cheer. Every channel is the parents’ section at track meet: Ready to erupt when their kid crosses the finish line, and equally ready to hop the fence and pick them up if they fall.
MDS ECOSYSTEM INFOGRAPHICS
The vast ecosystem now needed a map, ModernDataStack.XYZ maps out the components, and I think does an adequate job of categorising them.
Here is another map, with their criteria giving you an idea of the qualifying criteria. 3
MDS VENDOR COMPETITION HEATS UP!
Once the ball started rolling, there was a lot of money being poured into the space. New BI tools, new ELT, data quality, data reliability, observability, metrics, semantics, all started being picked over.
I wrote a blog comparing dbt and Dataform. Dataform was acquired as mentioned, and dbt took centre stage, centre diagram.
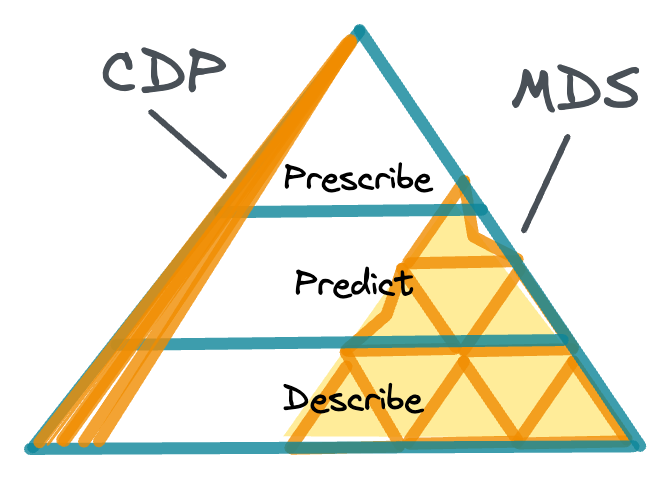
Two big themes were Reverse ETL and CDP:
Another somewhat-in-the-weeds, but fun to watch part of the landscape has been the tension between Reverse ETL (again, the process of taking data out of the warehouse and putting it back into SaaS and other applications) and Customer Data Platforms (products that aggregate customer data from multiple sources, run analytics on them like segmentation, and enable actions like marketing campaigns).
Reverse ETL was always a tricky thing. I like the idea of reverse ETL, but ultimately it would often build on very weak foundations:4

The CDP space also sort of heated up, and had significant overlap with MDS. The MDS gave you the tools to construct your own solution, and design the specifics to suit your needs, whereas the CDP kinda gave you much deeper capabilities, but less control (for the customer analytics niche).
FIRST ENTERPRISE VENDOR MDS OFFERINGS
Enterprise oriented MDS style tools and even direct clones started cropping up. The awkwardly named Coalesce was the first early dbt alternative since Dataform (Coalesce is also the name of dbt’s conference). I don’t know much about it.
MDS GARTNER MAGIC QUADRANT
There isn’t a fully fledged Gartner Quadrant. The whole point of MDS was all the unbundled solutions. There was a post on their forum. I predict we will see a “new wave” once all the tools are more consolidated and Gartner figures out how to position all of this.
I guess there are likely enterprise equivalently branded MDS style solutions that have happened. The only funny one I could find within 5 seconds of Googling was IBM Gen z/X.
OFFERINGS TO SOLVE MDS PROBLEMS
I almost wrote a blog decrying the state of things when I was spammed by an ex digitisation evangelist crypto expert, now selling data-something-dot-AI. Selling magic and then supplying junior analysts with git and SQL just stank of an enterprise sales cycle. This was indicative of the beginning of the end.
DON'T DO MDS / ENTERPRISE MDS
Data mesh was the funniest part of the entire data hype cycle. Effectively a fully fledged framework to decentralise data ownership, it read like a Business School Blockchain Certification (apparently, I didn’t read it). The response from the MDS pure snark. Pedram had the last word here. I guess maybe you had to be there.
There was heated posturing on Linkedin about the failure of MDS to properly address the problem of data modelling. Data Vault, Anchor modelling. How about a full circle all the way back to one big table?
This was also an Enterprise / Startup culture clash, but probably mostly a mutual lack of context and incompatible cadence. A 100 person SF startup growing beyond terminal velocity vs a declining mid-tier bank in the Bavarian hinterland aren’t going to meet each other with much common language. I wrote something about that here:
Phase 3: Involution / Stagflation
The movement has picked the low-hanging fruit of their object-level goals. Artistic movements have created enough works that it’s hard not to seem derivative. Intellectual movements have explored most of the implications of their ideas. Political movements have absorbed their natural base and are facing organized opposition. It’s still possible to do object-level work, but unless you’re a hard-working genius, someone will have beaten you to most good ideas

The cracks started to show in a few ways: cost, complexity, BI tools, sprawl.
Cost:
Snowflake et-al being super expensive was the first ominous crack. When interrogated, massive cloud bills often weren’t attributable to any value. It was presumed when these at kick off that they would be both expensive and lead to value. The expensive part was duly stomached but then the value part was late to the party.
ELT, synonymous with MDS, came under cost pressure. People realised that the work was pretty predictable and so cheaper, better, faster options became abundant.
And then AWS, Salesforce and Snowflake all began to murmur about ‘zero-ETL’ which basically meant they will co-access or whatever the data that is in Salesforce from Snowflake. Basically ruining the Fivetran business model.
“What if we could eliminate ETL entirely? That would be a world we would all love. This is our vision, what we’re calling a zero ETL future.
dbt:
Dbt was really just a victim of success, when you push into the unknown you will find out, and dbt found out. Before dbt, teams kept their reliance on a data warehouse simple and un-collaborative. One engineer would generally be responsible, they would have de facto veto on data modelling changes. dbt democratised that:
Did we achieve more collaboration on an analytics code base? ✅
Did we achieve more leverage through reusable and modular code? ✅
Did we also buy more complexity, resulting in longer maintenance and debugging cycles? Unfortunately, also ✅ 🤓
Turns out the price of enabling people to build a more complex code base is… a more complex codebase, and everything that comes with that.
Solving one problem and in doing so creating another is the essence of progress. I give dbt a pass here. Nonetheless, things got very complex, and not just limited to dbt.
There were numerous hot takes pointing to the shortcomings of dbt, and a slew of dbt alternatives popped up, all “faster horses” in my mind. We need cars.5
dbt having raised a ton of money, had to do layoffs and quickly figure out a business model.
Complexity:
You could be lead to believe that you need one from each of the following “MDS categories”. However most teams generally limited themselves to a BI tool, a database, an ETL tool and dbt.
The issue was the abundance of overlapping options.
Team size:
The other awkward thing to address was the growth in MDS team size. I worked with a team that wanted to double their data team from 20 to 50. MDS became known to run on human middleware:
Cash is injected. This means more employees of all sorts are hired. More employees increases the demand for more reports and analytics. More demand means more human middleware is created in the Clueless layer when you adopt the Modern Data Stack paradigm of throwing everything into your cloud data warehouse of choice.
More Clueless human middleware creates more tables, tables, tables to many more reports and KPIs and metrics. They have to buy new products and hire new people to manage the complexity.
This criticism was semi-reasonable6, but honestly I think this is often just the cycle of technology. Something comes along, presents an opportunity to differentiate, it works for some, it doesn’t work for others. People need to be involved. How many people? Probably a few. Oops too many. OK less people.
A more primary issue with buying anything is knowing if you are ready for it. Does this company need a better data capability? Falling behind is a real risk, that compounds!
The Data Stack was sold broadly, for some it worked, quite often it didn’t.
BI tools:
Business Intelligence tools continued to underwhelm, primarily because of the split between traditional reporting and exploratory analytics.
The paradigm of “reporting” is in my mind a dead end. Like delivering a menu and then never taking an order, BI tools were informative instead of interactive.
Traditional BI just don’t move the needle in the same way that newer tools like Hex do. (Hex described this paradigm in deleted article, they now position themselves as a data tool that does reporting too). I use Hex daily. It is relatively cheap, it works very well and has sufficient depth to replace a fair chunk of MDS and technology infrastructure too.
To be fair to BI tools, they were the last mile delivery problem built on a relative house of cards, so were pretty much destined to be the pain cafe.
Sprawl
There was Vocal Criticism from product analytics people about the sprawling nature of MDS.
Product analytics is a mature side-car to the MDS, and the tooling built by Posthog et al is generally end-to-end integrated. From their perspective, the MDS approach led to poor outcomes:7
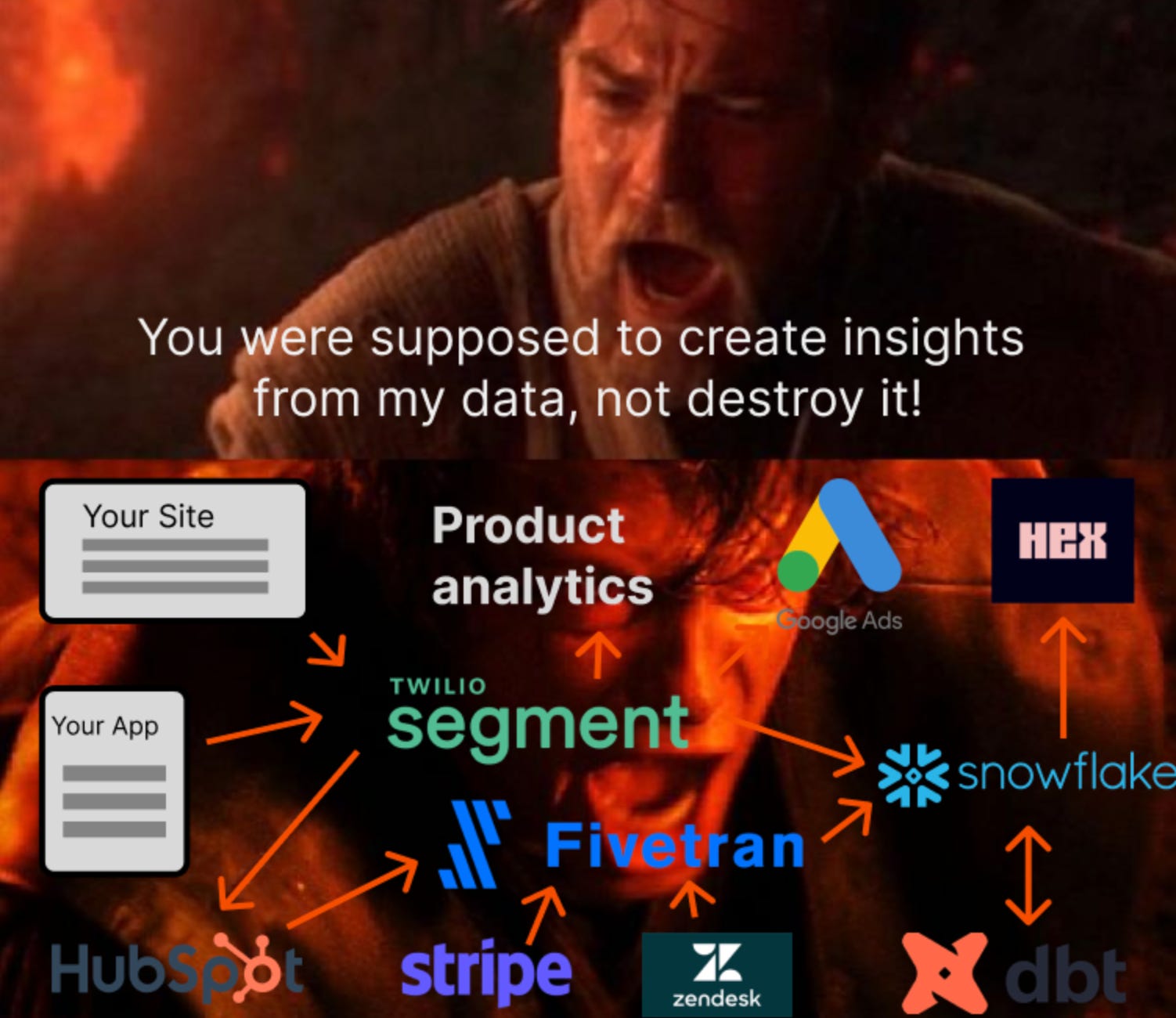
Those are a few of the criticisms that illustrate the point. Essentially the belleweather for the change in direction of the flock.
MDS IS DEAD POSTS
There were a few. This became a bit of a trope. Meta analysis of the trope is far more palatable. Hope you agree.
BACK TO BASICS MOVEMENT
There was always talk of a bundling. In essence the MDS was unbundling, and at some stage the tide would turn.
This was actually discussed at length in early 2022, where most everyone agreed that the unbundled approach was great for many things (experimentation, investing, entertainment, curiosity), but it wasn’t very productive.
MDS LATE ADOPTERS
There is still the MDSFest:
“A community-led celebration of ideas and perspectives on the modern data stack”.
Sounds great but I literally just came across it researching for this blog so I don’t actually know much about it
I don’t know where this video comes from but I think it demonstrates the idea that one person can pull together an entirely viable, semi-scalable data platform from the best of the open-source stuff, as was always intended. Silver lining.
EVANGELISTS MOURN STATE OF WAY
Some of the early evangelists mourned their loss. It did literally feel magic. You could achieve so much with so little. This was a reality.
A shrinking pie makes zero sum games more likely too. A shrinking pie means you have to work pretty hard just to stem the flow:
Everyone Wants a Piece of the Pie, Nobody Wants to Bake
…
if you don’t build things to solve a pain you’ve had in the hopes that it’ll solve someone else’s, if you don’t give away your hard work for free, then kindly, please, shut the fuck up.
Matt Turk knows all about all of this, having documented the data space for ages:
The MDS is now under pressure. In a world of tight budgets and rationalization, it is almost too obvious a target. It’s complex (as customers need to stitch everything together and deal with multiple vendors). It’s expensive (lots of copying and moving data; every vendor in the chain wants their revenue and margin; customers often need an in-house team of data engineers to make it all work, etc). And it is, arguably, elitist (as those are the most bleeding-edge, best-in-breed tools, serving the needs of the more sophisticated users with the more advanced use cases).
Overfunded startups, overcrowded teams, too many compute credits, too much badly structured SQL and lots of criticism.
The substance boiled down:
MDS was a series of relatively experimental tools strung together to demonstrate varyingly good levels of Product Market Fit, but not quite demonstrating an ideal operating model .
The result is a great target for more refined, more niche, bundled equivalents.

Phase 4: Postcycle
At some point, everyone realizes you can’t get easy status from the subculture anymore.
The people who want easy status stop joining,
and the movement stabilizes in a low-growth state.
END OF MDS STATUS GAMES
There is less attention and so less opportunity for status games. Most people have some trusted source of information and they rely on it, less interested in the minutia and more worried with whatever their pressing problems are.
A large chunk of data practitioners are now product focussed, in role, in company, in orientation. This is sensible as product is probably one of the best maturation directions, as it was a primary consumer of data outputs. ex-Data know how far to trust the data systems and what lies they tell. The same applies to operations.
MDS CONSOLIDATES WITH FOCUS
The data systems are largely good enough and so the bottleneck becomes what to do with the data. Data engineering was the bottleneck. In January 2022 I gave the opinion that Data Engineering was no longer the primary bottleneck to delivering insights/value/whatever.
Now in August 2023, I will now say that the Data Function is no longer the primary bottleneck in delivering insights/value. A good data team can ingest, model, analyse and distribute insights pretty easily. The challenges are now more subtle:8
Track 1: “All I want is to know what's different”
Track 2: “The emotionally informed company”
Track 3: “The truth is out there The only thing stopping us from finding it is us”
Track 4: “Will we ever have clean data? Probably not, but maybe we can work with messy data”
Matt Turk describes where things go from here:
The convergence of streaming and batch processing is an evergreen, and important theme. So is the convergence of transactional (OLTP) and analytical (OLAP) workloads
This Analytics vs Operational thing is critical. All I will add is that all data problems stem from the fact that the blue and a pink blob are handled by different teams.
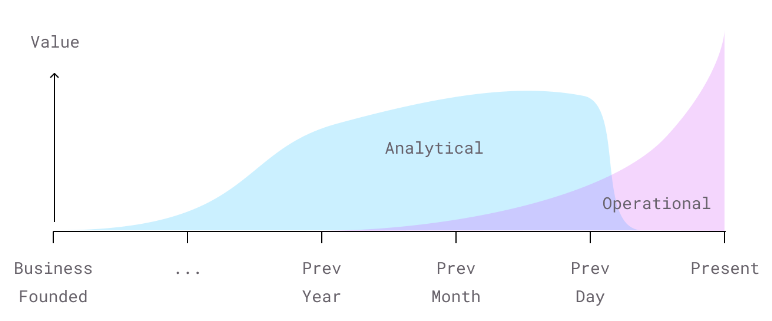
MDS LEFT US WITH MORE / PRACTITIONERS STILL CARE
The whole argument around MDS now mostly dusty, it can simply be described as a good idea that explored all the avenues and turned over all the stones.

Data technology was just a nightmare before, and a better solution is always necessary. The unbundling of the big systems into discrete elements was effective, and allowed people to experiment, learn, share and iterate on that cycle towards something that was very effective. Timo Dechau describes this:
The funny thing about evolution and potentially the one often missed out. Evolution is never linear. It branches out, explores, and creates massive amounts of variants. That is the beauty of it.
But it is also why there is never “the” next. But hundreds of next. And out of them, at some point, we will see a step changing the ways in such a good way that we could declare it as a new paradigm.
We are not there yet. But we can already see the branches, which is exciting.
He has another good line on of thinking that maybe Product and MDS will converge.
Product analytics on top of your events in your data warehouse. No more weird data loadings and enrichment (where most of them never worked). And mostly, no two setups for classic BI and product analytics use cases. We spent some more time with this approach later.
IN CLOSING
STILL REAL PROBLEMS TO BE SOLVED
The opportunities are there. My core issue with MDS was that data modelling remained a complete nightmare. As the SaaS systems that run a business got more complex, the effort to consolidate went up and the accuracy of the consolidation went down.
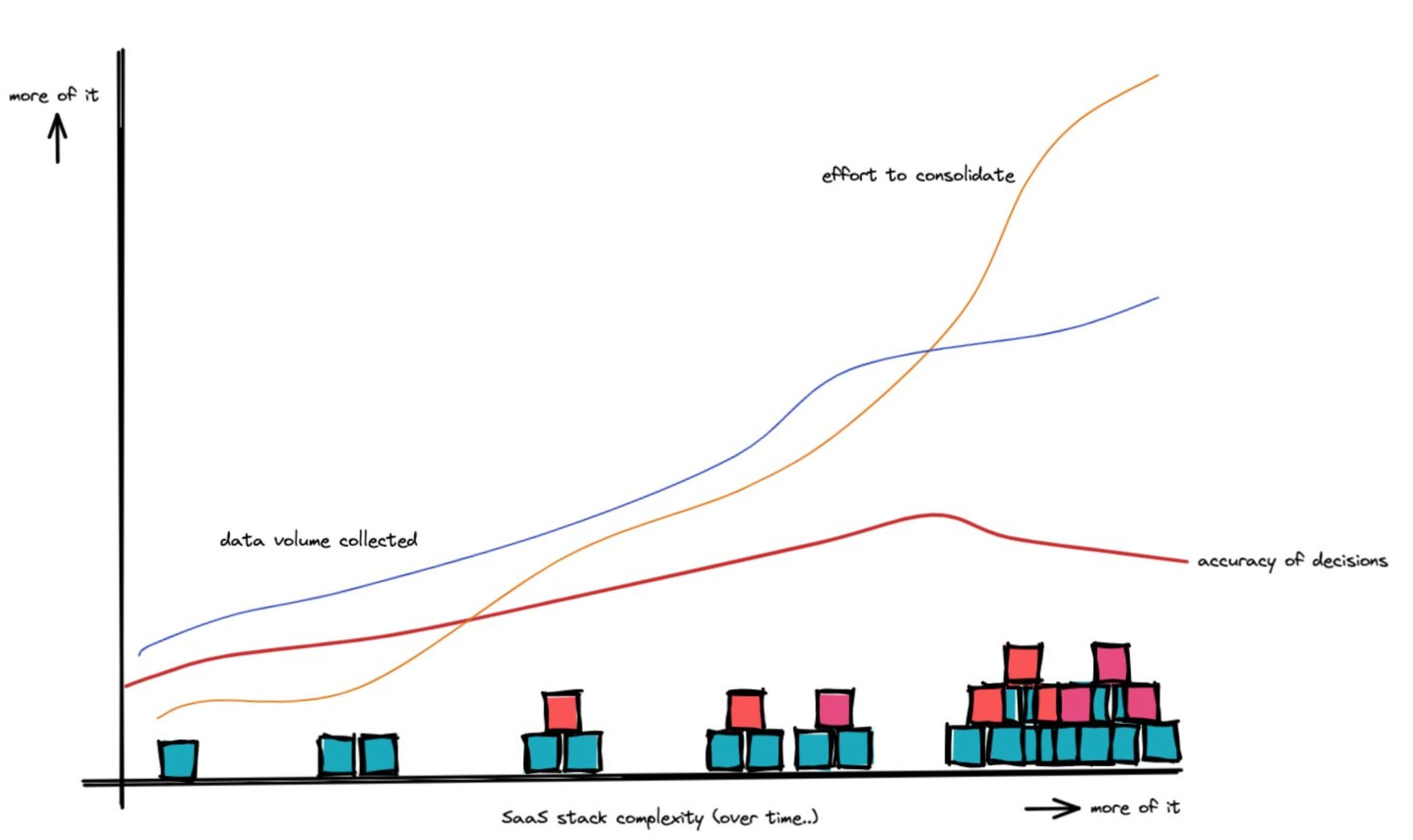
My take on data modelling:
There is an optimum level of data modelling done by software developers building apps and not just leaving it to the data team (Analytics vs Operational)

There is more work to be done exposing better data models via API from SaaS companies, and especially internally.
There absolutely has to be better (easier, pre-populated, more automated, less fragile, less complicated) data modelling techniques.
The immediate future for data modelling involves an important role in the next big thing
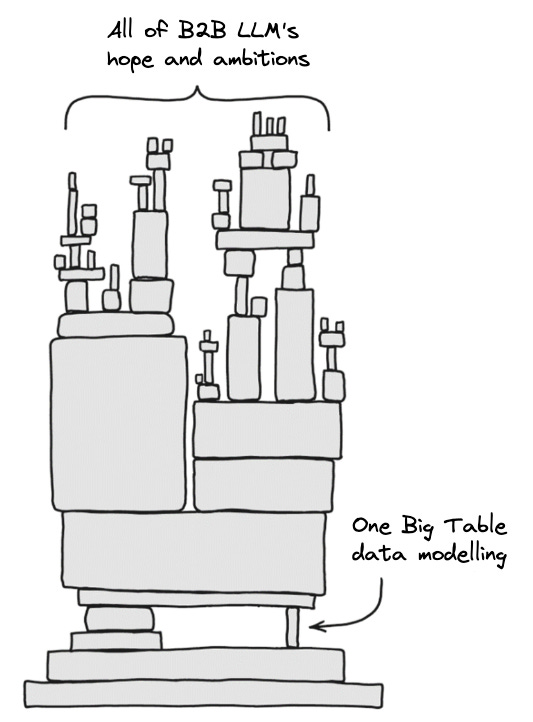
Jacob epitomised the true spirit of MDS - he built a data analytics “in a box” using entirely open source tools. It just seems like the absolute best way to demonstrate the value of the idea:
TLDR: A fast, free, and open-source Modern Data Stack (MDS) can now be fully deployed on your laptop or to a single machine using the combination of DuckDB, Meltano, dbt, and Apache Superset.
I started a small consultancy, of which we never had more than 4 or 5 people operating at any one time, but we worked with many great companies and some exceptional ones. I never pushed that hard on this as the learning balance quickly falls in the favour of the client (initially you learn, then once you’ve stopped learning then they start to benefit, and you just hopefully get paid enough).
Based on those criteria, I will riff a bit and say that in 2023 and onward, the following are clear requirements for buying data tools
The product must be aware of the data warehouse, the CRM and the related tools. Complementary technology is essential.
The intro-demo-trial-buy process must be accessible without hand holding, screening calls, hidden pricing and other crap. (once in growth phase out of beta etc)
Some form of value must be obvious and demonstrated within 3 hours of the trial.
Niche verticalized versions of the Reverse ETL concept do very well, as do niche CDPs.
My two favourite cars - Malloy and Relational.ai are both sensible concept cars that take a novel approach to the heart of the problem - data modelling is a nightmare!
What started out as reasoned rapidly became directed at individuals that kinda gave you that awkward vibe that is difficult to engage with but to me indicated the signs of the end.
There is some irony that they then propose Posthog as a Data warehouse and CDP, but I’ve used Posthog and it is a good product analytics tool.
These read as if you asked chatGPT to write a song list for an angsty B2B data team leader’s third album